Hvad er OpenAI o1, og hvordan er denne model bedre end GPT-4o?
Den 12. september 2024 introducerede OpenAI, der er kendt for ChatGPT, sin nye serie af modeller for kunstig intelligens kaldet OpenAI o1. I denne artikel analyserer vi, hvordan OpenAI o1 adskiller sig fra GPT-4o, hvad dens styrker er, og på hvilke områder den kan bruges.
Hvad er OpenAI o1?
Det er en ny familie af chatbots, eller mere præcist, sprogmodeller baseret på kunstig intelligens, designet til at løse komplekse eller særligt vanskelige opgaver, der kræver nøjagtighed og logisk tænkning.
I øjeblikket omfatter o1-familien:
- o1-preview - hovedmodellen (stadig i en tidlig version, som det fremgår af ordet »preview«),
- o1-mini - en lettere og hurtigere model, som er særlig effektiv til kodning.
Der er en vis symbolik i selve navnet »o1«:
Men til komplekse ræsonneringsopgaver er det et betydeligt fremskridt og repræsenterer et nyt niveau af kunstig intelligens. Derfor sætter vi tælleren tilbage til 1 og navngiver denne serie OpenAI o1.
Forskelle fra GPT-4o
OpenAI o1 er et alternativ til GPT-4o, men ikke en direkte erstatning. Ellers ville modellen blot hedde GPT-5.
Da OpenAI o1 er på et relativt tidligt udviklingsstadie, kan den endnu ikke gøre mange af de ting, som GPT-4o kan. For eksempel understøtter den ikke upload af filer og billeder.
Men o1-modellerne udmærker sig ved nøjagtigheden af deres svar, konsistensen og logikken i deres ræsonnementer, hvilket gør det muligt at anvende dem med succes på områder som f.eks:
- Kvantefysik,
- Genetik,
- Medicin,
- Softwareudvikling.
OpenAI o1 genererer ikke blot et svar på et spørgsmål, men opbygger en kæde af ræsonnementer. Derfor kan det tage længere tid for modellen at svare end for andre chatbots - typisk 5-10 sekunder og i nogle tilfælde op til 20-30 sekunder. Det er ikke så lang tid, at det bliver en reel ulempe. Den omhyggelige overvejelse af svar gør OpenAI o1-modellerne mindre tilbøjelige til at hallucinere sammenlignet med deres konkurrenter. Hallucinationer er, når en chatbot finder på fakta ud af den blå luft og giver falske oplysninger.
OpenAI o1's styrker og evalueringer
Ovenfor har vi allerede nævnt styrkerne ved OpenAI o1, f.eks. nøjagtigheden af svarene og den svage modtagelighed for hallucinationer. Lad os nu se, hvordan alt dette omsættes til tal: hvad o1-modellen scorer i forskellige tests.
OpenAI o1 ligger i den 89. percentil på konkurrencedygtige programmeringsspørgsmål (Codeforces), placerer sig blandt de 500 bedste studerende i USA i en kvalifikation til USA's matematikolympiade (AIME) og overgår menneskelig nøjagtighed på ph.d.-niveau på et benchmark af fysik-, biologi- og kemiproblemer (GPQA).
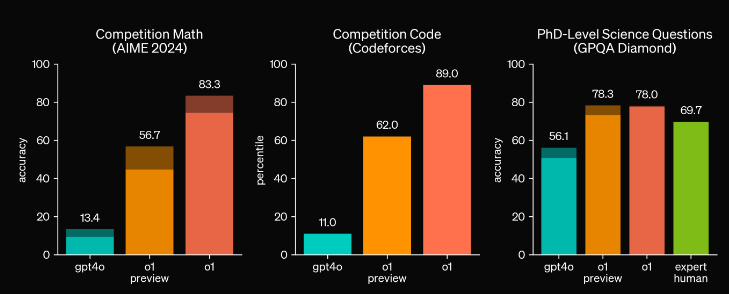
Fra venstre mod højre: Konkurrencematematik, konkurrencekode, videnskabelige spørgsmål på ph.d.-niveau
Ved AIME-eksamenerne i 2024 løste GPT-4o kun 13 % af problemerne korrekt, mens o1 scorede 83 %.
I GPQA Diamond-testen, som omfatter videnskabelige spørgsmål på ph.d.-niveau inden for fysik, biologi og kemi, klarede o1-modellerne sig endnu bedre end menneskelige eksperter. Tidligere har kunstig intelligens ikke været i stand til at overgå mennesker i denne test.
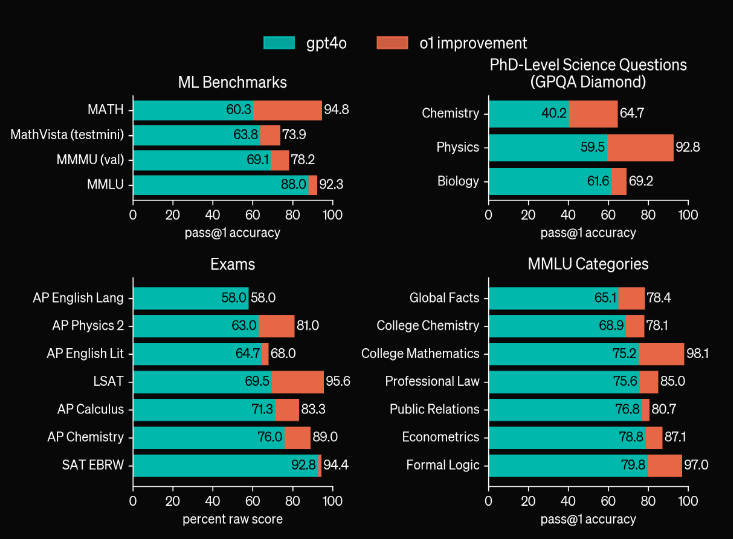
Turkis: GPT-4o, Rød: o1
Billedet ovenfor viser o1's ekspertise i discipliner, der spænder fra matematik til engelsk litteratur. MMLU-testen omfatter 57 kategorier. o1-modellen vandt i 54 af dem. Kun 7 af dem passer ind i billedet:
- Globale fakta
- Kemi på college
- Matematik på college
- Professionel jura
- Offentlige relationer
- Økonometri
- Formel logik
Interessant nok klarer o1-mini sig bedre til kodning end o1-preview, som både Codeforces- og HumanEval-benchmarks viser:

Benchmarks for kodningsfærdigheder
Ud over eksamener og akademiske benchmarks evaluerede OpenAI også den menneskelige præference for o1-preview vs. GPT-4o i:
- Personlig skrivning
- Redigering af tekst
- Computerprogrammering
- Dataanalyse
- Matematisk beregning
I denne evaluering blev menneskelige undervisere vist anonymiserede svar fra o1-preview og GPT-4o, og de stemte om, hvilket svar de foretrak.
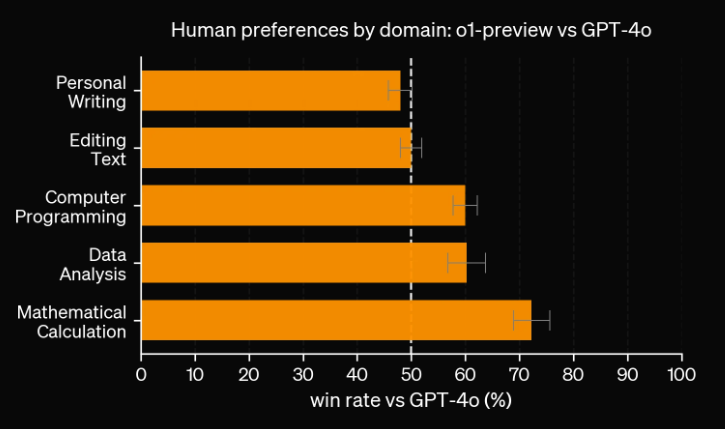
o1-preview gevinstprocent vs GPT-4o (%)
o1-preview foretrækkes frem for GPT-4o med en stor margin i ræsonnementstunge kategorier som dataanalyse, kodning og matematik. Men o1-preview er ikke foretrukket i nogle naturlige sprogopgaver som at skrive og redigere tekst, hvilket tyder på, at o1-preview-modellen ikke er velegnet til alle brugssituationer.
OpenAI o1 vs. andre store sprogmodeller
OpenAI o1-preview er virkelig smart. Hvor smart? Baseret på den norske Mensa-test har den en IQ på 120, hvilket er betydeligt højere end andre testede sprogmodeller. Toppen på grafen repræsenterer den gennemsnitlige menneskelige IQ. Alt til venstre for toppen er under gennemsnittet, mens alt til højre er over gennemsnittet.
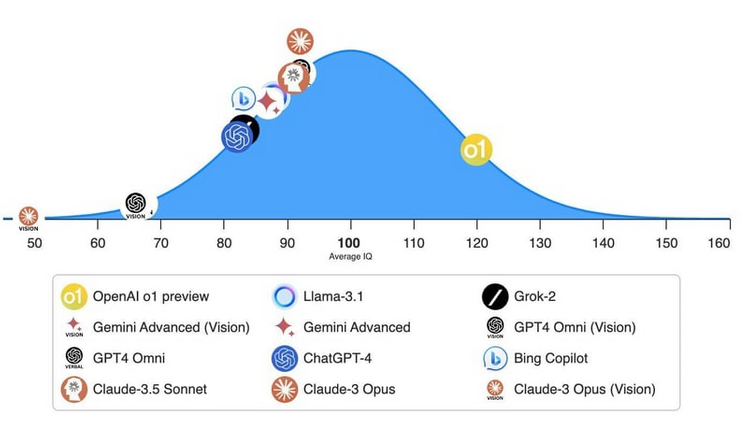
OpenAI o1 slår konkurrenterne med flere længder, både i store benchmarks og i hjemmelavede tests.
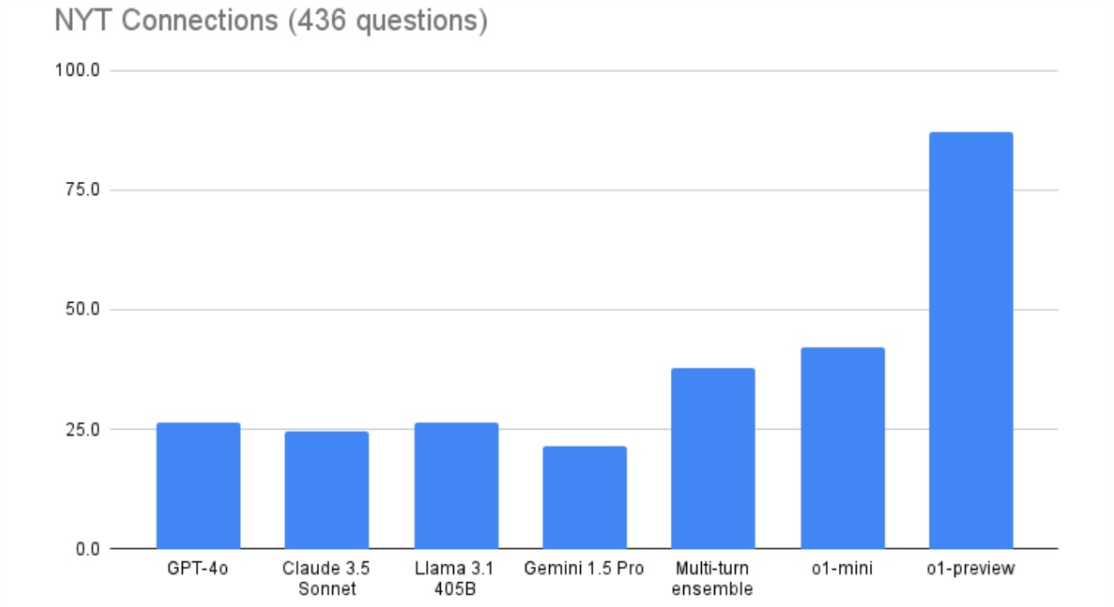
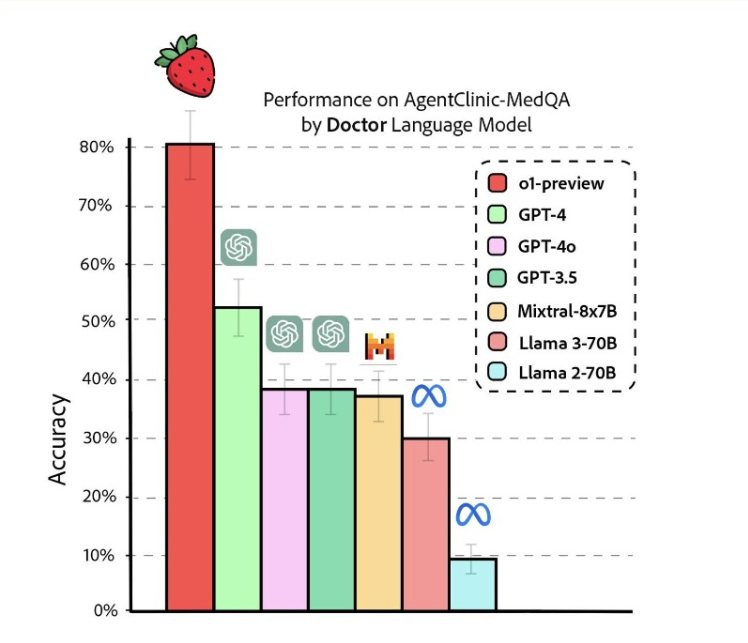

Du behøver ikke engang at forstå de tests. Alt, hvad du behøver, er at se OpenAI o1 øverst.
Kæde af tanker
Modellerne i o1-serien er trænet i at ræsonnere og opbygge en kæde af tanker. Chatbotten giver således ikke kun et færdigt svar, men viser også den vej, den tog for at nå dertil. Det kan være meget interessant at følge denne vej.
Lad os se på et af de sværere spørgsmål fra den tidligere nævnte IQ-test.
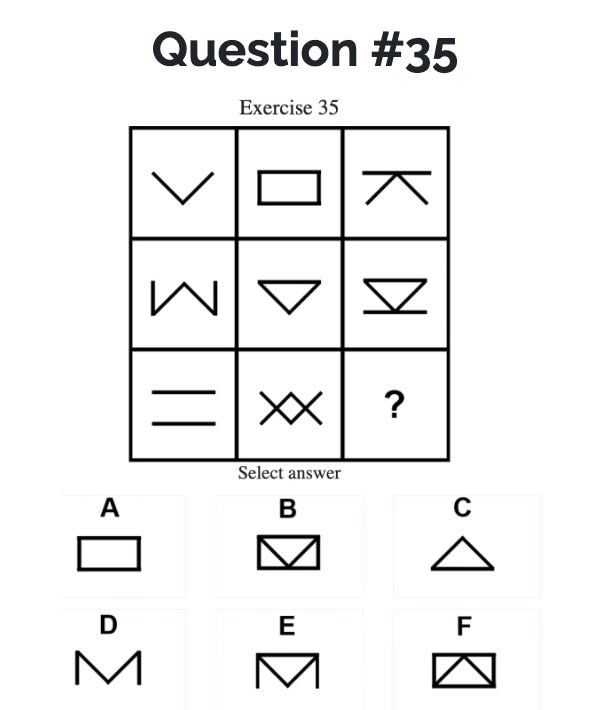
Robotten valgte mulighed D som svar, og her er dens forklaring:
Mulighed D - Ved at analysere mønstrene i gitteret ser vi, at hver kolonne kombinerer visse komponenter for at inkludere alle elementer (V, V på hovedet, rektangelets sider) i tredje række. I den tredje kolonne er komponenterne Rleft og Rright (rektangelets sider) endnu ikke dukket op. Derfor er det korrekte svar for den tomme celle mulighed D, som inkluderer det normale 'v' og de to sider af rektanglet, hvilket fuldender sættet af komponenter for den kolonne.
Lad os nu se på et enklere puslespil (ikke fra IQ-testen):

Spørgsmål: Hr. og fru Smith og deres to børn er en typisk amerikansk familie. Ifølge en af deres mere snakkesalige naboer: George og Dorothy er blodsbeslægtede. Howard er ældre end George. Virginia er yngre end Howard. Virginia er ældre end Dorothy. Hvis to og kun to af disse udsagn er sande, hvad er så fornavnet på hvert familiemedlem?
Kæde af tanker: For at løse dette puslespil skal vi bestemme fornavnene på hvert familiemedlem ud fra de givne udsagn og betingelsen om, at præcis to udsagn er sande. Lad os nedbryde informationen trin for trin.
Nu viser modellen familiemedlemmerne, deres mulige roller og navne; analyserer udsagnene og finder ud af, hvilke af dem der er sande, og hvilke der er falske. Baseret på alt dette giver modellen det endelige svar.
Svar på spørgsmålet: Hr. Smith er George, fru Smith er Virginia, sønnen er Howard, datteren er Dorothy.
Konklusion
o1-preview-modellen er i stand til at ræsonnere logisk, hvilket er nødvendigt for at løse komplekse videnskabelige og matematiske problemer. o1-mini-modellen er genial til at skrive kode. Men begge OpenAI o1-modeller er ret snævert specialiserede værktøjer, de er ikke så alsidige i deres anvendelser som GPT-4o, og de er ikke egnede til mange rutinemæssige eller kreative opgaver: arbejde med tekster, litterær oversættelse, redigering. Men inden for deres domæne (matematik, natur- og eksakte videnskaber) er OpenAI o1-modellerne uden sidestykke.