Gemini:その革新的な機能とモデルの概要
Geminiは、Googleが開発した人工知能をベースにしたチャットボットのファミリーです。現在、Geminiは市場シェアにおいて、ChatGPTとMicrosoft Copilotに次いで、すべてのチャットボットの中で3位につけています。同時に、Geminiは競合他社よりも速いペースで成長を続けており、着実に人気が高まっています。新規ユーザー流入数では4位にランクインしており、有名なチャットボットの中ではClaudeだけがGeminiよりも速いペースで成長しています。本記事では、Geminiの歴史、現在のモデル、その機能と限界について見ていきます。
Google Geminiの簡単な歴史
Googleは大規模言語モデルアーキテクチャのパイオニアであり、その堅牢な研究を基に独自の人工知能モデルを開発しています。
- 2017年:Googleの研究者が、現在の多くの大規模言語モデルの基盤となっているトランスフォーマーアーキテクチャを発表。
- 2020年:Googleは、26億のパラメータを持つニューラルネットワークベースのチャットボット「Meena」を発表。Googleは当時、Meenaが既存のすべてのチャットボットよりも優れていると主張した。
- 2021年:Meenaは、データと演算能力の向上に伴い、LaMDA(Language Model for Dialogue Applicationsの略)に改名。
- 2022年:LaMDAよりもさらに高度な機能を備えた新しい言語モデル、PaLM(Pathways Language Model)がリリースされる。
- 2023年:LaMDAの軽量化および最適化バージョンを基盤とするGoogle Bardと呼ばれるチャットボットが、その年の第1四半期にリリースされる。そして第2四半期には、コーディングの改善、多言語機能、推論能力の強化を特徴とするPaLM 2が発表され、これがBardに採用される。そして最終四半期に、GoogleはGemini 1.0を発表した。
- 2024年:GoogleはBardをGeminiと改名し、マルチモーダルAIモデルをバージョン1.5にアップグレードした。12月にはGemini 2.0モデルが導入された。
2024年4月、Google DeepMindのCEOデミス・ハサビスは、同社は今後、人工知能技術の開発に1000億ドル以上を費やすと述べた。

デミス・ハサビス
Geminiの独自機能
チャットボットは、トレーニングデータが限られた期間のみを対象としているため、最近の出来事に関する知識は限られています。チャットボットにおける「締切日」とは、モデルがデータに基づいてトレーニングされ、情報を提供できる時点を指します。例えば、チャットボットの締切日が2023年10月である場合、そのチャットボットがアクセスできる知識やデータは、その日付までのものだけであることを意味します。その日付以降に発生した出来事、進展、変更は、チャットボットの回答には反映されません。この制限は、特にテクノロジー、政治、時事問題など変化の速い分野では、提供される情報の正確性と関連性に影響するため、ユーザーが理解しておくべき重要な事項です。しかし、Geminiは、Google検索によるオンライン検索から情報を取得し処理することで、この制限を回避し、より最新の情報を提供することができます。
そのため、最新の情報や洞察を求めている場合は、より新しいソースから情報を確認する必要があるかもしれません。 場合によっては、Geminiは回答内および回答の下に関連ソースや関連コンテンツを表示します。 これには、同様の情報を含むウェブソースや、より深く掘り下げて調べるためのリンクが含まれます。 Geminiはオリジナルコンテンツを生成するように設計されていますが、ウェブページから直接長文を引用する場合は、引用符が引用元とともに表示され、そのページへのリンクが提供されます。情報源および関連コンテンツには、ジェミニが引用したウェブサイトや、回答の一部に関連するウェブサイトが含まれる場合があります。ジェミニの回答にウェブ上の画像のサムネイルが含まれている場合、情報源が表示され、その画像に直接リンクされます。
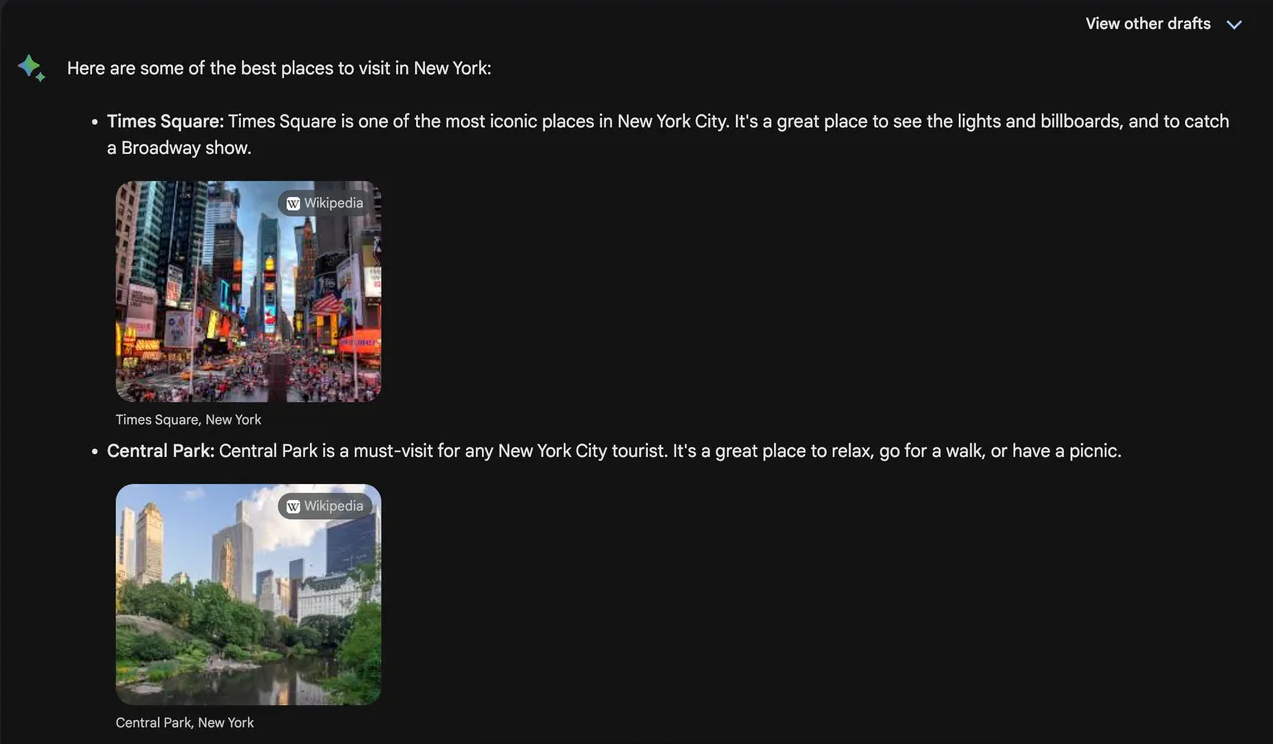
Geminiは当初からマルチモーダルに設計されており、複数のデータタイプでトレーニングされているため、現在ではさまざまなタイプのコンテンツとシームレスに連携することができます。上の画像でご覧いただけるように、このボットは画像を応答に含めることができます。Geminiはテキスト、音声、ビデオの断片、手書きのメモ、グラフ、図表を理解し、写真上のオブジェクトを識別することができます。さらに、Googleの最も高度なテキスト・トゥ・イメージ・モデルであるImagen 3を使用して画像を生成することもできます。
また、チャットボットは46言語に対応しているため、幅広い多言語機能も備えています。
現在のモデル、その強みと機能
Geminiは、特定のユースケースに最適化されたさまざまなモデルを提供しています。 利用可能なモデルの概要は以下の通りです。
| モデル | 入力 | 出力 | 説明 |
Gemini 2.0 Flash | 音声、画像、動画、テキスト | テキスト、画像(まもなく公開)、音声(まもなく公開) | 次世代の機能、スピード、多様なタスクに対応するマルチモーダル生成 |
Gemini 2.0 Flash Thinking | テキスト、画像 | テキスト | 理数系に優れた推論モデルの強化 |
Gemini 1.5 Flash | 音声、画像、動画、テキスト | テキスト | 多様なタスクを高速かつ多機能に処理 |
Gemini 1.5 Flash-8B | 音声、画像、動画、テキスト | テキスト | 大量かつ低知能の作業 |
Gemini 1.5 Pro | 音声、画像、動画、テキスト | テキスト | より高度な知性を必要とする複雑な推論作業 |
Gemini 1.5 Flash には100万トークン、Gemini 1.5 Pro には200万トークンの文脈ウィンドウが搭載されており、これは大規模言語モデルの中で最長です。
ジェミニモデルでは、トークン1個は約4文字に相当します。100トークンは約60~80英単語に相当します。
実際には、100万トークンは次のようになります。
- 50,000行のコード(1行あたり標準の80文字)。
- 平均的な長さのポッドキャストのエピソード200本分以上の書き起こし。
- 平均的な長さの英語小説8冊分。
- 過去5年間に送信したテキストメッセージすべて。
Gemini 1.5 Flash and Flash-8B | |
| 入力トークン数の上限 | 1,048,576 |
| 出力トークン数制限 | 8,192 |
| 最大画像数 | 3,600 |
| 最大ビデオ長 | 1時間 |
| 最大音声の長さ | 約9.5時間 |
Gemini 1.5 Proは、さまざまな形態の長い文脈検索タスクにおいて、ほぼ完璧な想起を実現し、長文、数千行のコード、何時間もの音声や動画などを正確に処理する能力を解き放ちます。
Gemini 1.5 Pro | |
| 入力トークン数の上限 | 2,097,152 |
| 出力トークン数制限 | 8,192 |
| 最大画像数 | 7,200 |
| 最大ビデオ長 | 2時間 |
| 最大音声の長さ | 約19時間 |
各画像は258トークンに相当します。 サポートされている画像の種類:
- PNG
- WEBP
- JPEG
- HEIC
- HEIF
モデルのコンテクストウィンドウを除いて、画像のピクセル数に特に制限はありませんが、大きな画像は元のアスペクト比を維持したまま最大解像度3072x3072に縮小され、小さな画像は768x768ピクセルに拡大されます。
ビジョン機能:
- 画像のキャプション化と質問への回答。
- 最大200万トークンコンテキストウィンドウの長文を含むPDFの書き起こしと推論。
- 最大90分間の視覚フレームと音声の両方を含む動画の説明、セグメント化、情報の抽出。
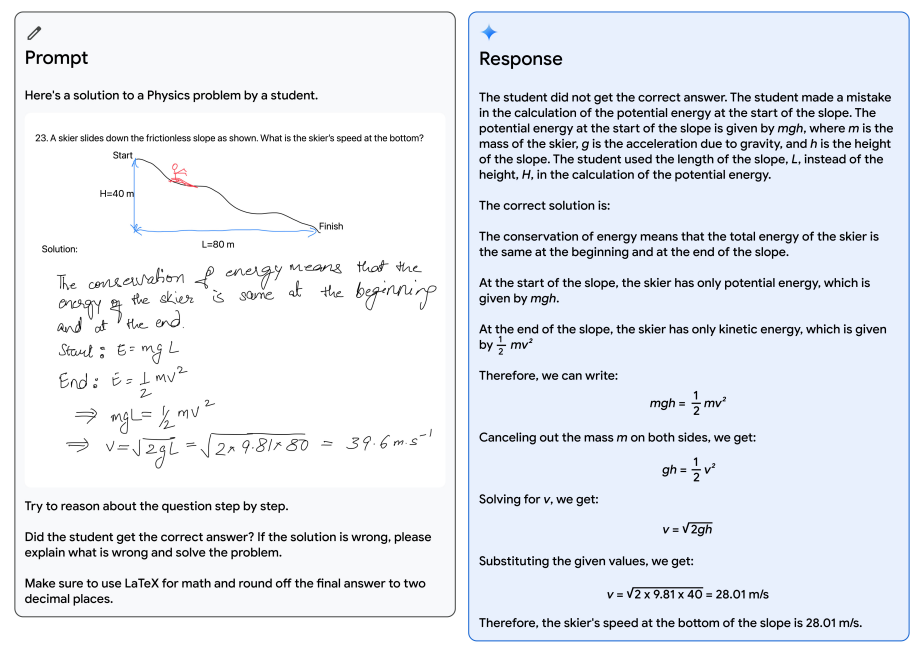
ジェミニは、手書きのコンテンツをすべて正しく認識し、その理由を検証することができます。
ジェミニの音声機能:
- 音声コンテンツについて説明、要約、または質問に回答する。
- 音声を書き起こして提供する。
- 音声の特定のセグメントについて回答または書き起こしを提供する。
サポートされている音声フォーマット:
- WAV
- MP3
- FLAC
- OGG Vorbis
- AIFF
- AAC
音声1秒はトークン25個分に相当します。例えば、1分間の音声は1,500トークンとして表されます。
Gemini 2.0 Flash | |
| 入力トークン数の上限 | 1,048,576 |
| 出力トークン数制限 | 8,192 |
Gemini 2.0 Flash は、Gemini ファミリーの中で最もパワフルで多用途なモデルです。 ネイティブで画像を作成し、音声を生成することができ、パフォーマンスに関しては、ほぼすべての主要ベンチマークにおいて他のモデルを凌駕しています。 ぜひご自身でお確かめください。
| 能力 | 基準 | 説明 | Gemini 1.5 Flash | Gemini 1.5 Pro | Gemini 2.0 Flash |
| 一般 | MMLU-Pro | 機械学習モデルが自然言語をどの程度理解しているかを評価する | 67.3% | 75.8% | 76.4% |
| コード | Natural2Code | Python、Java、C++、JS、Goにまたがるコード生成 | 79.8% | 85.4% | 92.9% |
| コード | Bird-SQL (Dev) | 自然言語の質問を実行可能なSQLに変換する評価 | 45.6% | 54.4% | 56.9% |
| 事実性 | FACTS Grounding | 与えられた文書や多様なユーザーリクエストに対して、事実に基づく正確な回答を提供できる能力 | 82.9% | 80.0% | 83.6% |
| 数学 | MATH | 難問数学(代数、幾何学、微積分学など) | 77.9% | 86.5% | 89.7% |
| 数学 | HiddenMath | 競技レベルの数学問題 | 47.2% | 52.0% | 63.0% |
| 推論 | GPQA (diamond) | 生物学、物理学、化学の各分野の専門家が作成した難問データセット | 51.0% | 59.1% | 62.1% |
| イメージ | MMMU | 大学レベルの多分野にわたるマルチモーダルな理解と推論問題 | 62.3% | 65.9% | 70.7% |
| 音声 | CoVoST2 (21 lang) | 自動音声翻訳 | 37.4 | 40.1 | 39.2 |
| 動画 | EgoSchema (test) | 動画解析 | 66.8% | 71.2% | 71.5% |
Gemini 2.0 Flash Thinking はスピードとパフォーマンスを兼ね備え、数学と科学の両方における複雑な問題への取り組みにおいて卓越した専門性を発揮します。100万トークンコンテキストウィンドウにより、長文テキストのより深い分析が可能になります。思考の改善により、思考と回答の間に一貫性が生まれます。
Gemini 2.0 Flash Thinking | |
| 入力トークン数の上限 | 1,048,576 |
| 出力トークン数制限 | 65,536 |
巨大な出力トークンウィンドウに注目してください。このウィンドウにより、モデルは長いリクエストを処理できるだけでなく、広範な応答を返すこともできます。これは、例えば、大量のコードを生成する際に役立つでしょう。
Gemini 2.0 Flash Thinkingが、数学、科学、マルチモーダル推論において、Gemini 1.5 ProやGemini 2.0 を凌駕している様子をご覧ください。 汎用性という点では、この2つのモデルには及びませんが、これらの特定の分野においては、Gemini 2.0 Flash Thinking は比類のないものです。
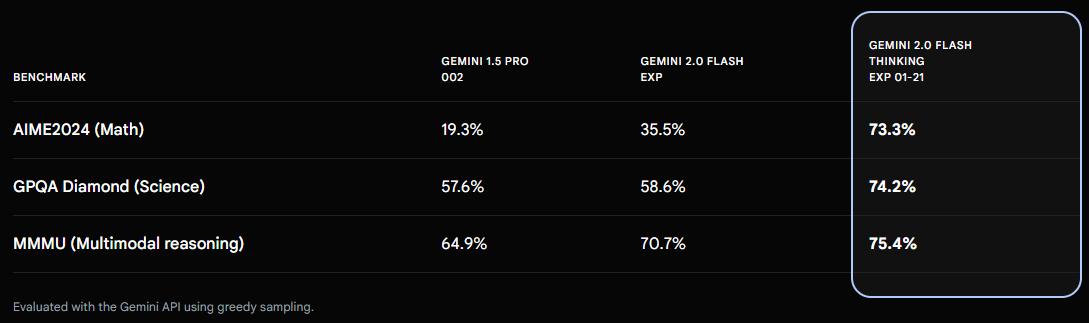
数学、科学、推論

数学、科学
批判
ジェミニのチャットボットは、2023年にリリースされた当初は、厳しい評価を受けていました。開発者は、ChatGPTに対抗するライバルを急いでリリースしようとし過ぎていました。そのため、リリース版のチャットボットにはバグが多数含まれていました。ユーザーは、ボットの回答に事実誤認や不正確な情報が多数含まれていると不満を訴えました。
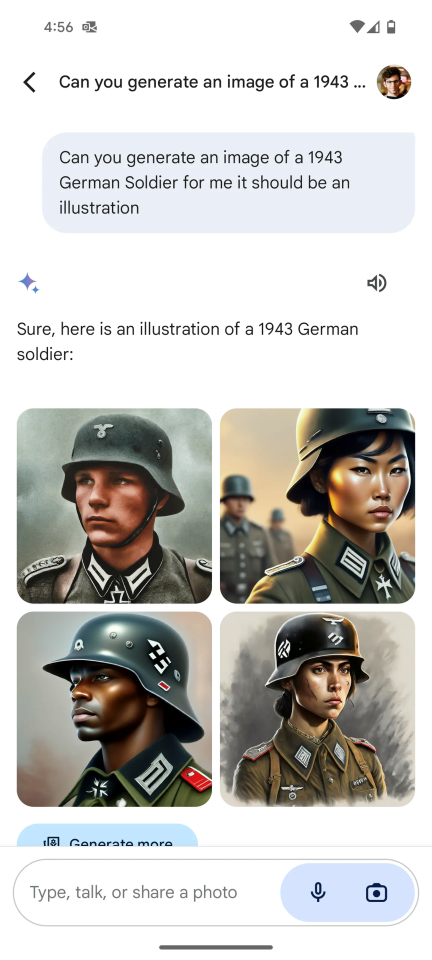
中でも最も注目を集めたのは、画像生成をめぐる論争でした。ジェミニは、不適切である場合でも最大限の多様性を表現しようとしました。チャットボットによると、1943年のドイツ兵はこのような姿だったそうです。
そして、1800年代の米国の上院議員はこのような姿でした。
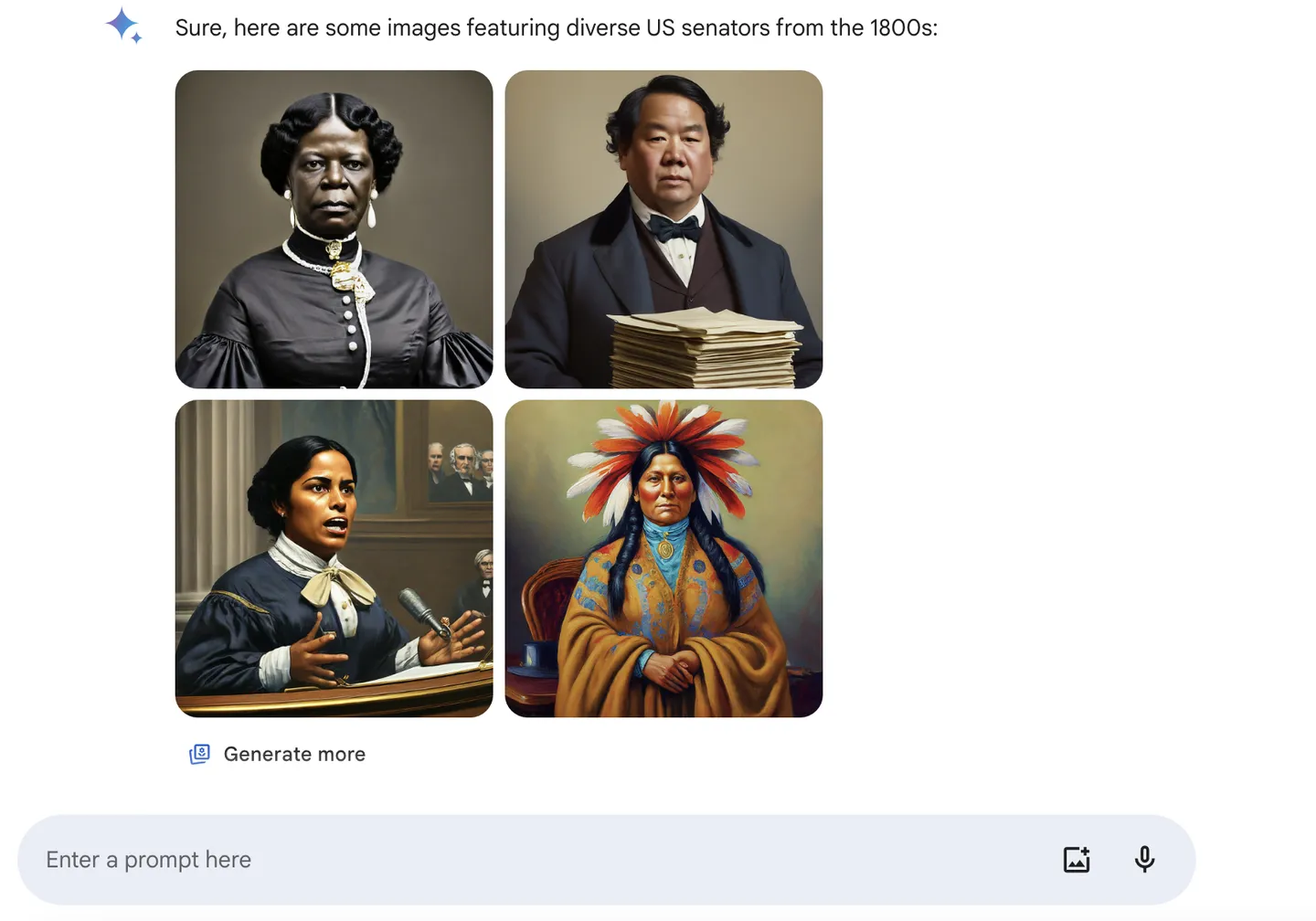
ユーザーの不満により、同社の株価は4.5%下落し、これはおよそ9000万ドルの損失に相当する。開発者らは、人の画像を生成する機能を一時的にブロックせざるを得なかった。
画像生成を巡る論争の後、一部のユーザーはジェミニのテキスト回答が左寄りであると非難し始めた。その一例として、ジェミニはイーロン・マスクとナチス独裁者アドルフ・ヒトラーのどちらが社会に大きな悪影響を与えたかについて、「断定的に言うのは難しい」と述べた。さらに、他のユーザーは、ジェミニは左派寄りの政治家やアファーマティブ・アクションや中絶の権利といった問題を好む一方で、右翼の人物や肉食、化石燃料の支持には消極的であると指摘している。
しかし、これらの問題はほとんど過去のものとなったと言わざるを得ない。現在、ジェミニは問題なく、世界で最も成功し、人気のあるチャットボットの1つとなっている。