ChatGPT 설정 이해: 온도, Top P, Presence penalty 및 Frequency penalty
ChatGPT 매개변수가 제공하는 유연성과 사용자 정의 옵션을 통해 ChatGPT는 다양한 작업을 위한 다목적 도구가 됩니다. 온도, Top P, Presence penalty 및 Frequency penalty와 같은 매개변수를 조정하여 사용자는 특정 요구 사항에 맞게 모델의 출력을 미세 조정할 수 있습니다. 창의적인 글쓰기, 정확한 답변 생성, 모델의 언어 스타일 형성 등 이러한 매개변수를 이해하고 활용하면 ChatGPT의 유용성과 효율성을 크게 향상시킬 수 있습니다.
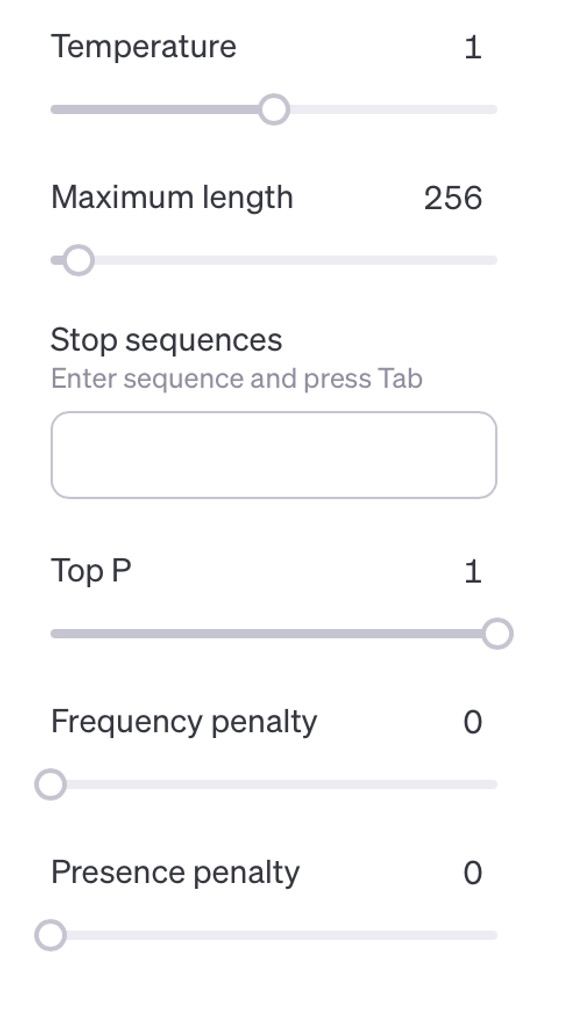
ChatGPT 설정
온도
온도는 생성된 응답의 무작위성을 제어합니다. 온도 값이 높을수록 무작위성이 증가하여 반응이 더욱 다양하고 창의적이 되고, 값이 낮을수록 더욱 집중적이고 결정적이게 됩니다.
창의적인 글쓰기 작업이나 브레인스토밍 아이디어의 경우 다양한 가능성을 탐색하기 위해 더 높은 온도 값(예: 0.8-1.0)이 선호되는 경우가 많습니다. 반면, 사실 기반 쿼리의 경우 또는 정확한 답변을 생성하는 경우 더 정확하고 신뢰할 수 있는 응답을 보장하려면 더 낮은 온도 값(예: 0.2-0.5)이 선호됩니다.
Top P
Top P 매개변수는 단어의 확률 분포를 잘라서 생성된 출력의 다양성을 제어합니다. 이는 다음 단어를 예측하는 동안 언어 모델이 검사하는 단어나 구의 수를 결정하는 필터 역할을 합니다. 예를 들어 Top P 값이 0.4로 설정되면 모델은 가장 가능성이 높은 단어나 문구의 40%만 고려합니다.
더 높은 Top P 값(예: 0.9-1.0)을 설정하면 더 넓은 범위의 옵션이 보장되어 더 다양한 응답이 가능해집니다. 이는 참신함을 원하는 창의적인 작업에 유용할 수 있습니다. 반대로, Top P 값이 낮을수록(예: 0.1-0.5) 가장 가능성 있는 항목으로 선택이 제한되어 응답이 더욱 집중되고 일관되게 됩니다.
온도와 Top P의 차이점은 무엇입니까?
Top P는 ChatGPT가 사용할 수 있는 토큰(단어 및 기호) 범위를 정의합니다. Top P = 1이면 언어 모델은 응답을 생성하는 동안 모든 토큰을 사용할 수 있습니다. Top P = 0.5이면 가장 가능성 있고 적절한/일반적인 옵션의 50%만 사용할 수 있습니다.
반면에 온도는 ChatGPT가 특정 토큰을 선택할 가능성을 결정합니다. 온도가 1이면 봇은 사용 가능한 모든(Top P 범위 내) 옵션에 대해 동일한 확률을 갖는 반면, 값이 낮을수록 더 자주 사용되는 단어 및 구문에 기울게 됩니다.
온도 및 Top P에 대한 최적 값
다양한 작업에 가장 적합한 온도 및 Top P 값은 클라이언트 또는 출판물의 특정 요구 사항 및 선호도에 따라 달라질 수 있습니다.
- 기사 작성의 경우, 낮은 온도 값(예: 약 0.5-0.7)과 중간에서 높은 Top P 값(예: 약 0.8-0.9)은 인공지능 모델의 창의적인 입력을 허용하면서 보다 집중적이고 일관된 기사를 생성하는 데 도움이 될 수 있습니다.
- 제품 설명의 경우 약간 높은 온도 값(예: 약 0.7-0.8)과 중간 정도의 Top P 값(예: 약 0.7-0.8)을 사용하면 잠재 고객에게 눈에 띄는 독특하고 매력적인 설명을 작성하는 데 도움이 될 수 있습니다.
- 언어 번역의 경우 낮은 온도 값(예: 약 0.5-0.7)과 중간에서 높은 Top P 값(예: 약 0.8-0.9)은 자연스러운 결과물을 유지하면서 정확한 번역을 보장하는 데 도움이 될 수 있습니다.
- 가상 비서 작업의 경우 중간 온도 값(예: 약 0.7-0.8)과 중간에서 높은 Top P 값(예: 약 0.8-0.9)을 사용하면 유익하고 매력적인 대화형 응답을 생성하는 데 도움이 될 수 있습니다.
- 콘텐츠 큐레이션의 경우, 온도 값이 높고(예: 약 0.8~0.9) Top P 값이 낮으면(예: 약 0.2~0.4) 관련성과 품질을 유지하면서 큐레이션된 콘텐츠의 창의성과 다양성을 더 높일 수 있습니다.
- 코드 생성 작업에는 정확성과 규칙 준수가 필요합니다. 0.1에서 0.5 사이의 낮은 온도 값을 설정하면 정확하고 오류 없는 코드를 생성하는 데 도움이 될 수 있습니다. 무작위성을 최소화하고 확립된 규칙을 준수하려면 0.2 정도의 낮은 Top P 값을 사용하는 것이 좋습니다.
Presence penalty
Presence penalty와 Frequency penalty 모두 반복을 방지하는 데 도움이 됩니다. 두 가지 모두 같은 단어를 반복해서 사용하면 불이익을 주지만, 약간 다른 방식으로 불이익을 줍니다. Presence penalty는 토큰의 발생 빈도와 관계없이 지금까지 생성된 텍스트에 토큰이 등장했는지 여부에 따라 불이익을 줍니다.
이를 통해 ChatGPT가 보다 다양한 어휘를 사용하도록 장려합니다. Presence penalty 값이 높을수록 페널티가 더 뚜렷해집니다.
Frequency penalty
Frequency penalty는 토큰이 지금까지 텍스트에 얼마나 자주 등장했는지에 따라 토큰에 불이익을 줍니다. 생성된 결과에서 동일한 단어가 과도하게 사용되는 것을 발견하면 이 매개변수의 값을 높일 수 있습니다.
Presence penalty를 높이는 것은 반복적인 문구나 아이디어를 사용하지 말라고 ChatGPT에 지시하는 것과 같고, Frequency penalty를 높이는 것은 같은 단어를 너무 자주 사용하지 말라고 지시하는 것과 같습니다.
Presence penalty 및 Frequency penalty의 최적 값
반복되는 샘플을 적당히 줄이기 위한 목적으로 적합한 벌점 계수의 범위는 일반적으로 0.1~1입니다. 그러나 반복을 크게 억제하는 것이 목표인 경우 계수를 2까지 늘릴 수 있습니다.
그럼에도 불구하고 이러한 증가로 인해 샘플 품질이 눈에 띄게 저하될 수 있다는 점에 유의하는 것이 중요합니다. 또는 의도적으로 반복 가능성을 높이기 위해 음수 값을 사용할 수도 있습니다.